The simpler times…

Rare historical photograph of a SysAdmin, an ancient species that would later evolve into modern DevOps, circa January 1999. The specimen, barely containing his excitement at the release of Linux 2.2 and the prospect of the upcoming LinuxWorld Expo, is performing the bi-yearly software patching ritual in production with his obligate mutualist (colloquially known as "the software vendor sales dude").
I started in tech in the late 90s after dropping out of college. My first metal server got compromised in two weeks. (Yes, phpMyAdmin . Yes, unpatched. Yes, still ashamed.)
Literally the first thing we deeply internalized in that era was to "very carefully review what you depend on, read all changelogs and patches, apply timely, always be up to date".
Pretty sure that sounds quaint, even alien, to most of the npm-dependabot-trigger-happy folks…
Nowadays, in the face of a sweeping, seemingly insurmountable onslaught of devastating supply chain incidents, some package managers started recommending to not update dependencies before a certain number of days (just to make sure, you know, that the idiots who go in front of you pay the price and spot the issues first…).
What has long been a staple of basic software security hygiene and vernacular wisdom is now considered harmful: do not update too soon, or expose yourself to ongoing supply chain attacks. Of course, not upgrading does expose you to active campaigns against (technically patched) upstream CVEs.
Damned if you do. Damned if you don't.
The old operating model was indeed fine in a much smaller, simpler tech world, in a more controlled and siloed environment, where you would depend on a handful of formally defined vendors that you could manually vet, and where complex supply chain issues and larger-than-life dependencies list were… not even a sci-fi concept.
The massive shift towards open-source over the past two to three decades (in part sustained by a better security story: "you benefit from much better community-driven scrutiny than with closed-source vendors!"… oh, sweet summer child…), along with the exponential increase in the size of ecosystems, brought massive new issues to light, painfully revealed through a chain of literally horrific "core dependencies" vulnerabilities (remember bind, openssl, or just log4j?) that have basically broken the entire internet, repeatedly.
The first "realization", probably mid 2010s: open-source maintainers are not just free labor, they are also overworked, under-equipped, wildly understaffed, and just as competent or incompetent as anyone else. Yet their work underpinned most software out there (and still do).
Add to that the profound flaws and inadequacies of hopelessly naive package managers, and software distribution as a category, the ineptitude of some of the new (very) popular stacks, and the increased pressure to race out competitors in the corporate industry, altogether breeding a culture that kept just the appearance of the previous one (the "always be fully patched" part), now devoid of substance, becoming essentially "just update everything, whatever it is, don't even look".
The notion of "supply chain vulnerability" became mainstream. The wider industry response was for the most part throw-your-hands-up-in-the-air: "We're on the latest version. Upstream will patch. What else do you want from us?"
The avant-garde would additionally engage with nicely packaged red-tape bureaucracy that did nothing to solve the root causes of the actual problem but made us all feel better, spoon feeding the comforting illusion that we were in control by creating additional work (for a nice little bundle of money of course): responsible disclosure programs and grand proclamation security policies, embargoes, CVEs, and the god-holy CVSS (super useful, right? RIGHT?), compliance processes, certifications…
Or in a more colorful language: "maybe openSSL will have more issues, but we don't know how to fix it, let alone rewrite it, we have no idea what exactly we use in it, and even if we would, we don't have time for that, and it would cost us more money than dealing with the occasional global fallout, so, let's just keep leaching blindly whatever they ship, we will just be as (in)secure as the rest of the world anyhow. Oh, hey, we are ISO certified."
Some form of "security in numbers (as long as I don't have to do anything)", as a twisted version of the original open-source idealistic promise of mutually beneficial communities.
And before you claim you never were one of us : look me in the eye and swear you donate to your OSS upstreams, and that you have never merge-bombed a Dependabot PR without reading the diff.
No you don't. And yes you did.
From supply chain vulnerability to supply chain compromise: the end of trust
It should be obvious to the reader at this point, or to anyone who lived through the past ten years (or anyone who has been paying attention since… check notes… 1984), that the industry itself did invite the next escalation.
If "the supply chain" is just (mostly) blindly trusted by about everyone without any actually useful verification, why even try to find an existing vulnerability in one of the links when it is much easier and cheaper to compromise developer accounts (or tools) and just ship a weaponized version of it?
In the mid 2020s, security is no longer (so much) about securing your own software (for the majority of the industry, modern frameworks and languages take care today of most of the security thorns you would have to fight with in the 90s, and pen-testing, audits, and static analysis are mature practices).
It is also a lot less about fixing issues in the code of your upstream dependencies (though far from solved as a general problem, important core pieces of infrastructure (DNS, TLS) have largely cleaned up their act, thanks to the half-reluctant support of the upper crust of the industry, and for everything else, we just gave up anyhow and basically wait for an upstream patch while the stuff is embargoed, doing crosswords with compliance checklists).
So, what is AppSec mostly about now?
It is about not being able to trust the supply chain itself. At all.
(if you need names, and just from the past 12 months: Shai Hulud, Nx s1ngularity, axios, TeamPCP, chalk / debug / qix, tj-actions/changed-files)
Ironically, we are technically much better equipped nowadays to handle supply chain hardening properly (in no specific order: encrypted transport no longer negotiable, content-addressability, OIDC / Fulcio, TUF, SLSA, 2FA, etc). Or maybe because of that, of the extra complexity and effort that using all of that correctly requires, getting adoption on best practices, better defaults, and reasonable investment in better tooling across the broader industry has been… underwhelming.
Provenance, no matter how good, will always have absolute-zero value if one does not consume it. Generally, securing the supply chain with hard technical solutions that require efforts has been surprisingly impervious to success, regardless of merits or value.
If you need convincing:
What percentage of companies doing software development today have somewhere in their stack a FROM registry.whatever/debian:latest?
For the record, I led the Docker distribution team back in 2014, rebuilding container image distribution from the ground up, on top of content-addressability, very intentionally to provide safe primitives for containerized software distribution. A seemingly ideal technical solution that was also a major usability faceplant leading to just about everybody using these soft-tags.
How many do not pin their GitHub actions to a sha, and do not understand what it means? How is that even legal? How many do, but still happy-merge dependabot PRs just bumping it to whatever is available right now, feeling “secure” because of that?
How many blindly do a go install github.com/someorg/somerelease@v1.2.4 thinking "it is fine"?
“go is safe”, “domain is github.com”, "package version is not latest", "we like that library and have used it for years", “it has many stars”.
What could possibly go wrong here?
And on the other side of the equation, the same complacency meets the (often singular) human factor.
All-powerful maintainers of said third-party dependencies fall for phishing, or fail to manage credentials securely by a hundred miles, or simply vanish.
Hastily misconfigured GitHub repositories or CI pipelines leave sensitive tokens with alarming permissions literally up for grabs.
Judgment day
To some extent, the situation was at a seemingly stable point.
Yes, not good, but business as usual.
We would all live through days of frantic running-around, rotating all secrets and bouncing prod, every now and then, then go back to doing presentations at DevOps Day. “How I recovered from the Nx compromise by not sleeping for 36 hours. Look at me!”. Sheesh.
What has changed of course over the past two years, but specifically for the past six months, is the seemingly irresistible ascent of coding agents usage in serious companies, that has turned the volume up to 11.
The quantity of code produced, merged (and not getting reviewed) has certainly increased (significantly). GitHub has just shared some of their platform numbers. We also have some of these frontier receipts. Whether AI does make senior engineers more (or less) productive is debated, but there is no denying that the last standing, already frail, human safety guardrail, the good old code review, has been trampled and overrun.
Reputable, professional companies are now looking at fully automating SDLC, by letting agents merge other agents code without human intervention.
The institutional CI itself is in no better shape. GitHub, of all, is indeed fighting significant scale issues, right now. Quite frankly, anyone who is paying attention and who still cares should just be screaming hysterically.
Without over-dramatizing, frontier professional software development lifecycle starts to look a lot like a runaway train with no human on board anymore.
Some are trying to revert things to the old ways (when was the last time this worked?), betting on a reckoning that will presumably never come.
What we should be saying out loud
Humans can no longer be in charge of the modern software supply chain security
This is no longer an open question.
We have failed at it already.
We are overwhelmed by non-actionable, mostly useless blanket "alerts", entirely ignoring most of them, and just stare at the remainder until some mythical upstream fixes it. No amount of band-aid "security tooling", dashboards and graphs will move the needle on that one.
We barely review code anymore. We no longer read dependencies patches and we do not even believe anymore in the old lie that someone else must have done it. Even when we could, we rarely patch upstream ourselves. Corporations with the means and will to, just privately fork or rewrite internally.
Rigid automated-updates tooling can not stay in charge of it either
Blind installation and blind updating dependencies continuously (a-la dependabot), as a least-worse solution, just blew out of the train already, becoming the number one vector of distribution for highly publicized supply chain compromises in the past 12 months.
“Latest” must die. Soft tags must die. Unpinned versions ranges must die.
I am literally paralyzed every time I have to run pnpm add on my laptop, and wish I had stayed in college and chosen a different career path…
Don’t get me started on “run that in a container”, please.
Updating has become a dangerous proposal. Not updating is still not an option (could it ever be? maybe, actually?), in ecosystems that for the most part have completely foregone the notion of any form of long-term maintenance.
Dependabot and siblings were a genuine and major progress five to ten years ago. Now they are just harmful.
Replacing them is just overdue.
Dependency updates are untrusted contributions
When you think about it, this was just insane in the first place.
When your project receives a pull-request, it is (should be) thoroughly reviewed and verified before merging.
But then, a dependency gets updated, and we just hit merge?
Where does that make any sense exactly?
How is a legitimately well-intentioned contributor to your project (possibly an employee) any more suspicious than anything coming from another GitHub project you do not control or actually know anything about?
Dependency updates must be considered as untrusted code contributions.
The whole conceptual difference we have built in twenty odd years separating "dependencies" and "direct code contributions" is but a mere illusion, built on a long-gone notion that is just wildly ridiculous when you seriously look at it: that you should trust your neighbor's house security more than you do yours.
The reactionary path is a dead end
Going back is not a strategy. The development velocity that AI has enabled is too big to counter, and betting on a reckoning is a losing trade. Whatever your feelings (or mine) are about it. If anything, it will get faster. Privately maintained forks, carefully vetted versions, multi-stage gating, registry proxying, three-months cooldowns: just the new sysadmin clutching Apache 1.3 config and going down with the righteous ship. It will not survive the industry's need for speed.
And yes, developers must own security. This one is a 30-year-old, tired story. It is still relevant. Security should be our problem. And it is way too serious to be left to security professionals alone.
“Securing” AI tooling is not the next AppSec frontier
Snake-oil vendors are already pivoting to the next moral panic: "Your software is secure, but what if the evil AI agents steal your stuff? Install pink-rubber-band-AI-endpoint-SOC-SIEM today!" Just moving the goalpost to whatever is scary this quarter.
The underlying issue has not moved.
Trust nothing. Verify everything.
“Everything” just got a lot bigger, and "verify" got a lot harder.
What we are building
If you agree that dependencies are essentially untrusted contributions, we need an approach fit for the realities of 2026.
Products like socket.dev and openSSF do good registry-intelligence work, but they sit outside the CI. They cannot see a full update event with its repository context (diff, codebase, build, configuration, attestations, runtime behavior) as one coherent transaction, and they cannot act on it.
The system we are building at Mendral lives inside the CI. It connects threat information, production event logs, source code, historical CI logs, and any custom signals you want to add, alongside secure sandbox environments and a set of dedicated tools (see Andrea's post on agent harness for how that is wired). The agent operates on triggers, at different stages of the lifecycle.
Concretely, here is what happens when a Dependabot-style PR lands. The agent reviews any new or updated dependency on every pull request. Typo-squatting, known bad versions, and OSV-flagged malware gets surfaced. That should be table stakes in 2026.
It gets more interesting when there is no formal red flag. The agent combines openSSF scoring, upstream publication patterns, ownership, and open issues to assess the scrutiny level a given dependency warrants. The age of the requested version is heavily weighted: less than 7 days old raises scrutiny, less than 72 hours maxes it out.
When scrutiny crosses the threshold, the agent spins up a secure sandbox, downloads the requested version, unpacks it, and inspects package and source for compromise markers: new post-install scripts, new transitive dependencies, a full review of any new code compared to the last known good version, runtime behavior. Then it comments on the PR with what it found, and either approves, requests changes, or blocks.
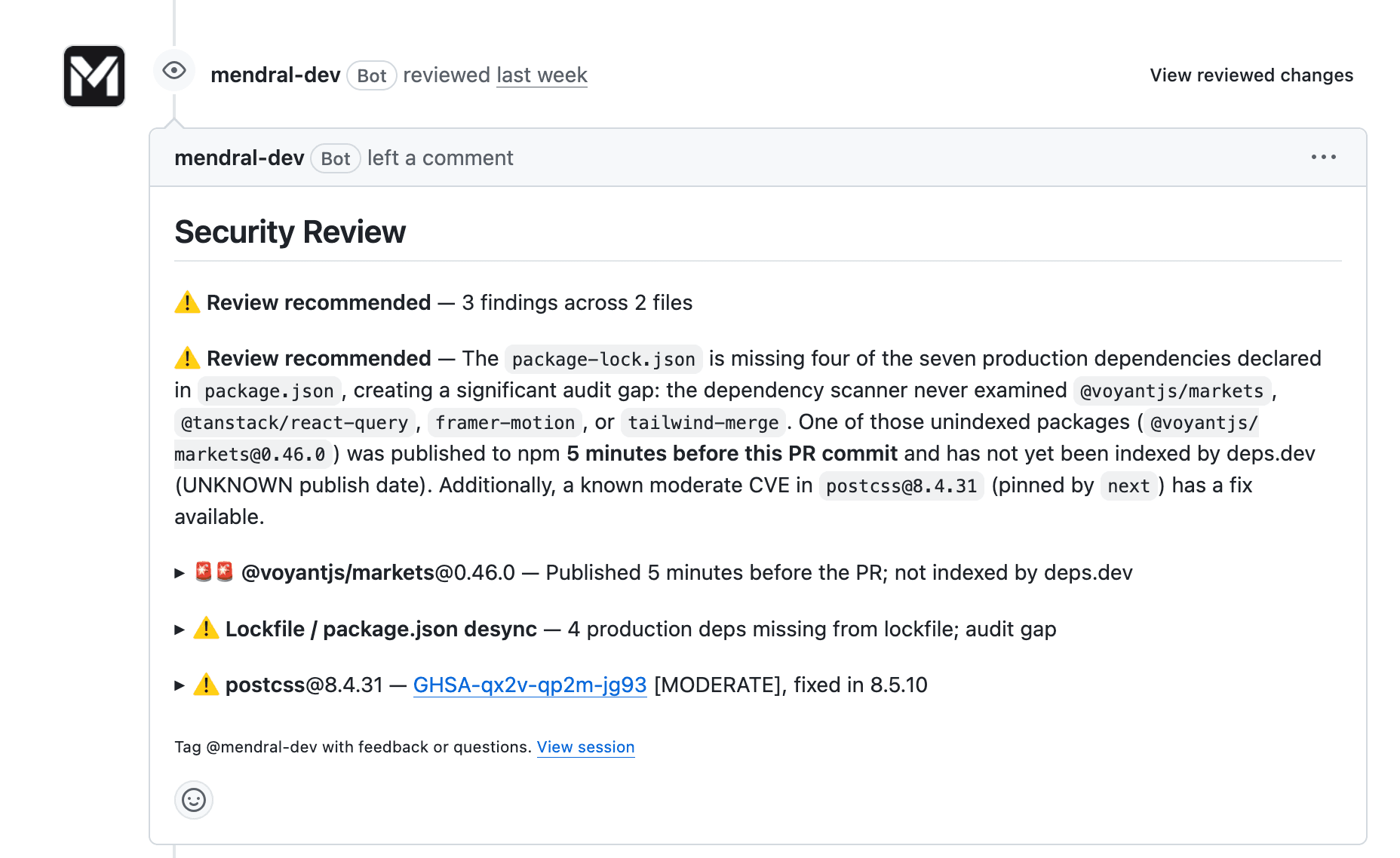
The same loop runs for known vulnerabilities. Every raw CVE is evaluated for reachability and blast radius in the context of the specific repository branch carrying the offending dependency. The operator gets an alert that actually answers "is our product affected?" and "if yes, how bad is it in our context?"
Where appropriate, the agent suggests remediation on the offending PR or opens a new one. The most straightforward fix is usually a non-vulnerable version. Sometimes it is hardening or rerouting the critical path.
And on every branch scan, the agent audits for posture weaknesses: unpinned GitHub actions, overly privileged tokens, soft tags, missing lockfiles. Pet peeves of mine, but also a lot more that you should not have to think about by hand.
"But it is AI, how can you trust it?"
You can't. AI is not a magic wand and (at least for now) cannot outperform the best humans. Mendral cannot and will not tell you "you are safe". Nobody can.
But AI is good at the mechanical, repetitive, exhausting parts: reading every diff of every dependency instead of skimming, checking changelogs for accuracy against actual changes, cross-referencing diffs against known compromise patterns, comparing a release against the previous N for behavioral drift. The work is volume-bound and pattern-heavy. Coupled with solid existing primitives (OSV, openSSF), an AI reviewer applied consistently to every dependency update is much more thorough than the "merge if CI green" review that is actually happening at every team I have worked on or led.
So, should you actually not update?
The title is not clickbait. Not the way it was meant in 2005, anyway.
You should not update your dependencies the way you currently do. Not by hand, because you cannot keep up. Not by Dependabot, because Dependabot is now the attack vector. Not by trusting "I have used this library for years", because the library is one phished maintainer away from shipping you a cryptominer.
Dependencies are untrusted contributions. Treat them as such. We are shipping the first version of this in our next platform release, in the upcoming days.
What I would love to see become table stakes: full code review on any dependency, regardless of profile or risk level. Scale will have to get solved first. And we can do more proactively: "show me every dependency in my stack that is abandoned, risky, deprecated, or menial, and give me PRs to replace them with better alternatives."
It is a first step.